Biology: Semester I |
|
| Sections: |
Introduction | Section 1 | Section 2 |
| Section Two: |
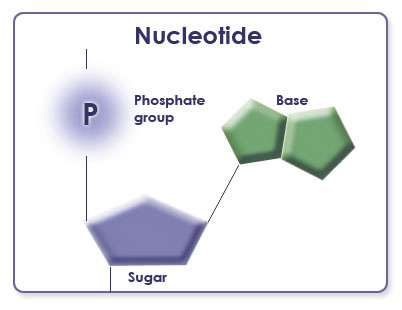
Biology: Chemistry of Life: Part Five 4. Nucleic acids: Nucleic acids are long chains made up of many smaller molecules called nucleotides. As shown below, a single nucleotide contains three parts: a 5-carbon sugar, a nitrogen-containing base, and a phosphate group. The sugar can be either ribose or deoxyribose. The base can be adenine, guanine, cytosine, thymine, or uracil. When nucleotides link together to form a chain, the phosphate group of one molecule attaches to the sugar group of the next molecule. The chain that forms can contain up to several million linked nucleotides. By linking these building blocks in a particular order, an organism stores coded genetic information. Organisms pass on this stored information to their offspring by making a copy of the nucleotide sequence. Probably the most well known nucleic acid is DNA, deoxyribonucleic acid. Characters on forensic science television dramas always seem to be DNA testing suspects! DNA evidence has been used to free wrongfully convicted individuals as well as to pinpoint guilt. During the summer of 2000, Celera Genomics and the Human Genome Project jointly announced the complete sequencing of the nucleotides that make up human DNA. Since then, news stories have reported discoveries of new DNA segments (genes) that influence everything from obesity and diabetes to alcoholism and Alzheimer’s disease. Our genes act as a musical score used by our cells to assemble a human being. Genes direct what goes where and in what sequence, and they partially determine what innate capabilities and flaws an individual will have. DNA cannot do this alone, however. RNA (ribonucleic acid) is another vital nucleic acid needed to create the proteins that are coded for in an organism’s DNA. RNA occurs in the nucleus as well as in the cytoplasm of a cell. RNA must translate the DNA code into a corresponding sequence of amino acids. The sequence of amino acids in the polypeptide chain determines the shape and function of the protein that will be created. Once created, the protein can perform its function in the body, whatever that function may be. Like DNA, RNA is composed of nucleotides. However, each RNA nucleotide contains a ribose sugar instead of a deoxyribose sugar. (The only difference between the two sugars is the presence of one oxygen atom—ribose has it but deoxyribose doesn’t, hence the name deoxyribonucleic acid.) So, how does our DNA “store” our genetic information and how does that sequence of nucleotides result in functional proteins? You might be surprised to realize that you already are familiar with the process of storing information in sequences. We do this all the time when we make meaningful words from a limited number of letters. The English alphabet has 26 letters and over 50,000 words. In contrast, DNA has four “letters” in its “alphabet.” They are the four bases, abbreviated A for Adenine, G for Guanine, C for Cytosine, and T for Thymine. These four “letters” combine in short three-letter sequences to code for 20 possible “words” (the 20 amino acids). These amino acid “words” can be arranged into an infinite variety of “sentences” (polypeptide sequences that can be modified further to make three-dimensional, functional proteins). In the English language, changes in the arrangement of the letters in words can alter the meaning of a sentence. The same thing can happen with DNA and amino acid sequences.
Congratulations on completing this section! In this section you learned about:
Now it’s time to take the section quiz. Please make sure to check your understanding of the topics above before proceeding to the quiz. After you have completed the quiz, continue with the unit.
| ||
|
© 2007 Aventa Learning. All rights reserved. |